
今更ながらCiv4の面白さを再発見して遊びまくっています。
基本的にはOACばっかりやっていますが、他のMODもちょっとやってみたくって目に止まったのがC2CというMOD。
今でも更新が行われている大作という事でプレイしようとしましたが、日本語対応していないかつ、Civ4から結構システムが変わっているので、ちょっとプレイしてみましたが良く分かりませんでした。
なので日本語化しようとして2日頑張りましたが、ちょっと途方も無いので断念しました。
途中までですがC2Cを日本語化するためのノウハウが溜まったので、折角なので共有させて頂きます。
このページを見てどなたかがやってくれたらなー的なことも思いつつ(笑)
C2Cとは

C2Cは、700を超えるテクノロジーがあったり、アルパカやキリンなどの動物がいたりなど、もう1つの新しいゲームと言って良い程にフルスクラッチされたCiv4のMODです。
プレイできていないので、紹介はこれくらいしか書けませんが、海外サイトで詳しく紹介されているので、気になる方はそちらを見るのが良いかもしれません。

C2Cを日本語化するための方法
概要
「今の時代、機械翻訳が優秀だからそれ使えば自動で日本語化出来るのでは?」と思いました。
- \Assets\XML\Textにあるxmlファイルに対して
- <English></English>で囲まれた中身を機械翻訳で日本語化して
- <French></French>として書き出す
って方法で余裕と思いました。
そんなことはなかったのですが・・・。
C2C日本語化のための開発環境
今回私は、
- Pyhton 3.7
- Google Cloud Translation API
で実装を試みました。
Pythonを選んだのは、「今まで使ったことがなく、勉強してみたかったから」、Googleを選んだのは「3万円分の翻訳料金が無料」だったためです。
作成したプログラムは、
- civ4_trans_google.py・・・Civ4MOD用の自動日本語化プログラム
- siv4_trans.bat・・・複数ファイル処理用のバッチファイル
の2つです。
civ4_trans_google.py
処理の概要は、
- 引数で渡されたファイルを開き
- <English></English>で囲まれた中身のテキストを取得して
- Cloud Translation APIで日本語化して
- <French></French>に書き出す
ということをやっています。
#!/usr/bin/python
# coding: UTF-8
def civ4_translate():
import sys, codecs
import time
import random
# 処理時間を計測
start = time.time()
# ファイルを開く
args = sys.argv
print(args[1])
f = open( args[1], 'r', encoding='utf-8')
#f = open( args[1], 'r')
# 1行毎にファイル終端まで全て読む(改行文字も含まれる)
# lines2: リスト。要素は1行の文字列データ
lines2 = f.readlines()
f.close()
# 出力用ファイルを開く
file_out = '.\out\\' + args[1]
f = open( file_out, 'w', encoding='utf-8')
# フラグを初期化
flag_eng = 0 # の下にを追記するため
flag_eng_2 = 0 # だけの行の時に、下のを取得するため
flag_eng_3 = 0 # だけの行の時に、で閉めないようにするため
flag_fr = 0 # だけの行の時に、下のを書き換えるため
count = 1
err_text = []
# 1行毎に処理を行う
for line in lines2:
# Englishなら
if line.count('') == 1:
# 同じ行にがあれば、内容をコピーして、日本語化
if line.count('') == 1:
# 内容を取得
index = line.find('')
line_data = line[ 11: index]
# 内容を日本語化
line_data_jp = line_data
#line_data_jp = g_trans(line_data)
# 出力
f.write(line)
flag_eng = 1
# だけの行ならそのまま出力
else:
f.write(line)
flag_eng_2 = 1
# Frenchなら内容を日本語に書き換えて出力
elif line.count('') == 1:
# 同じ行にがあればFrenchを出力
if line.count('') == 1:
f.write('\t\t' + line_data_jp + '\n')
# だけの行ならそのまま出力
else:
f.write(line)
flag_fr = 1
flag_eng = 0
# Spanishなら下にJapaneseを追加 *と思ったけど6番目らしいから未対応
#elif line.count('<Spanish') == 1:
# print line + '\t\t' + line_jp['translatedText'] + '\n'
# f.write(u'line' + '\t\t' + line_jp['translatedText'] + '\n')
# frフラグが立ってたらFrench - textを出力
elif flag_fr == 1:
# フラグによって出力方法を変更
if flag_eng_3 == 0:
f.write('\t\t\t' + line_data_jp + '\n')
else:
f.write('\t\t\t' + line_data_jp + '\n')
flag_eng_3 = 0
flag_fr = 0
# engフラグが立ってたら今の行と合わせてFrenchも出力
elif flag_eng == 1:
f.write('\t\t' + line_data_jp + '\n' + line)
flag_eng = 0
# eng2フラグが立ってたら、~の内容を日本語化してline_data_jpに格納、行まそのまま出力
elif flag_eng_2 == 1:
# 内容を取得
index = line.find('')
line_data = line[ 9: index]
# 内容を日本語化
line_data_jp = line_data
#line_data_jp = g_trans(line_data)
f.write(line)
flag_eng_2 = 0
# この行にがなかったらフラグを立てる
if line.find('') < 1:
flag_eng_3 = 1
#print(count)
else:
continue
# 上記以外ならそのまま出力
else:
f.write(line)
count += 1
# 特定のタイミングで処理状況をprintする
if count % 100000 == 0:
print(count)
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time) + "[sec]")
else:
continue
# ファイルを閉じる
f.close()
def g_trans(text):
# [START translate_quickstart]
# Imports the Google Cloud client library
from google.cloud import translate
# Instantiates a client
translate_client = translate.Client()
# The text to translate
#text = u'Hello, world!'
# The target language
target = 'ja'
# Translates some text into Russian
translation = translate_client.translate(
text,
target_language=target)
#print(u'Text: {}'.format(text))
#print(u'Translation: {}'.format(translation['translatedText']))
# [END translate_quickstart]
return translation['translatedText']
if __name__ == '__main__':
civ4_translate()
siv4_trans.bat
複数ファイルを一括処理するためのバッチファイル。
xmlファイルをこのバッチにドラック&ドロップするだけで一括処理できます。
こちらを参考に作りました。
@echo off :loop if "%~1" == "" goto end python civ4_trans.py %~n1%~x1 shift goto loop :end pause
プログラムの動作方法
上記プログラムを動作させるためには、
- Pythonの開発環境
- Cloud Translation APIの動作設定
が必要です。
Pythonの開発環境は、Anaconda3を利用しました。
インストーラー形式で全ての設定を自動で行ったくれるので楽です。

Cloud Translration APIの設定は、Google公式ページを見ながら行いました。
いくつか設定方法を解説しているサイトもあるので、導入に詰まった方は検索してみると良いかもしれません。

しかも、従量課金制なので使った後に請求が来ます。ご注意下さい。
私は今回結構使ったのでどれだけ請求されるかヒヤヒヤしてます(汗
2万円分までは無料とのことですが、それに収まってるかどうか超心配・・・。
途中まで日本語化した結果
日本語化は断念しましたが、途中までは日本語化出来ました。
こんな感じになりました。
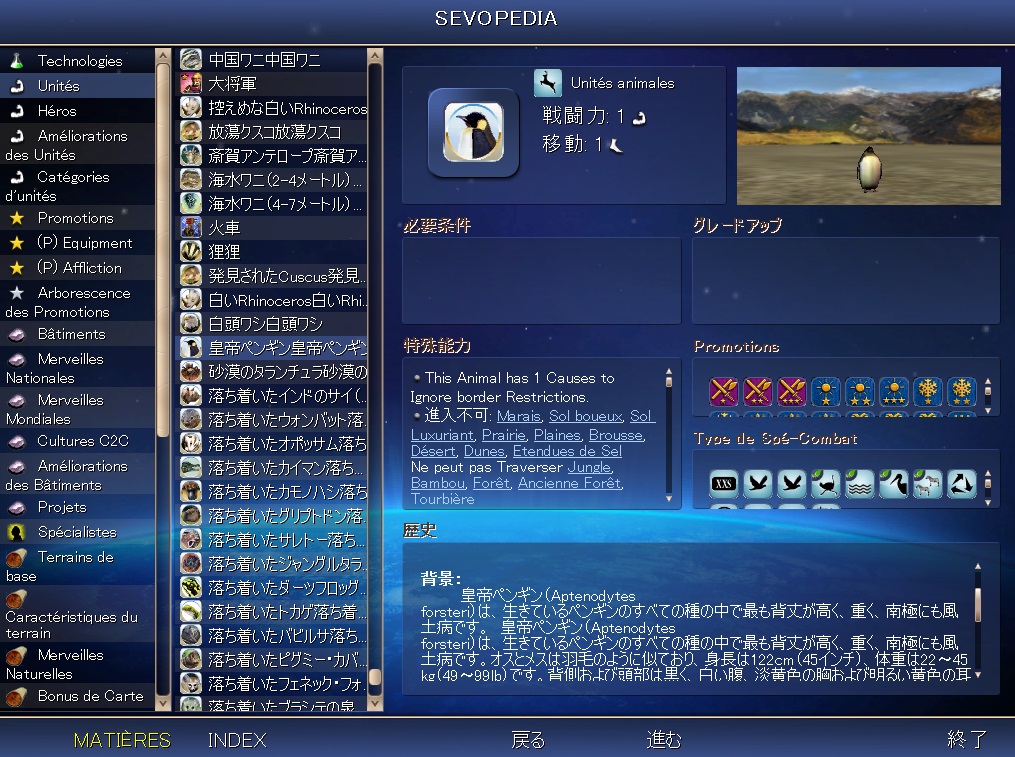
画像では、Animals_CIV4GameText.xmlを上記の方法で日本語化したものを適用しています。
同じ内容が連続したりはしていますが、英語の原文よりは分かりやすくなったと思います。
一応、作成したAnimals_CIV4GameText.xmlを置いておきます。
日本語化断念に至った経緯
<English></English>だけじゃなかった
<English></English>だけかと思いましたが作業を始めると、
<English>
</English>
や
<English>
<Text></Text>
</English>
などなど、当初想定した以外の例外が結構出て対応が大変でした。
Civ4の中身をいじるのは初めてだったので、例外がこんなに多いものとは思いませんでした。
ファイルが読み込めない
Pythonでファイルを読み込もうとした際に、どうしても読み込めないファイルがありました。
- Bonus_CIV4GameText.xml
- Captives_Build_CIV4GameText.xml
- CIV4GameText_Warlords_C2C.xml
- Features_CIV4GameText.xml
- Terrain_CIV4GameText.xml
の5つです。
これ以外にも当初は読み込めないファイルが有りましたが、文字コード変換ツールを使うことで読み込めるようになったファイルもありますが、上記の5つだけはどうしても読み込むことが出来ませんでした。

Pythonは文字コード関係に弱い?みたいなので、他の言語を使うと良いかも?
翻訳にかかる費用が膨大
Cloud Translation APIを使うのにはお金が掛かります。
100万文字で2,000円ほど。
無料で使える3万円以内でできるかと思いましたが、思いのほか文字数があるし、プログラムをテストするためにも結構使いました。
んで、「お金を掛けてまでやらなくても良いかな」と思ったので、断念しました。
また、Google翻訳を裏技チックな方法で無料で使う方法も見つけましたが、怒られたら嫌なのでやめました。


機械翻訳が完成したらGitHubで共有して、おかしなところはみんなで直せば良いかも?
OACで十分なのでは?
英語のままC2Cをやりましたが、英語が分からないためかいまいち面白くない。
C2Cの日本語化作業をしているうちに、「OACでやってない文明もまだ全然あるし、ReunionとかIoTとかもまだやってないから、C2Cを日本語化する作業時間をプレイ時間に回した方が楽しくね?」みたいな感じになってきました。
まあ、当初想定していなかった上記の問題が出て、1日で終わると思ってたのが2日掛かっても先が見えない状態だったので、「C2Cはまあいっか」ってなった次第です。
おわりに
C2Cの日本語化作業ですが、途中までやったので共有のためまとめさせていただきました。
誰か引き続きやってくれないかなー?(チラッ
C2Cの日本語化は断念しましたが、Civ4熱はまだ熱いのでMODはちょっといじってみたいとは思っています。
ReunionからOACへ、セ○バーやマ○さんを移したいんじゃー!